Searching Datasets for Analysis
The most common use of the grid for analysis is the submission of jobs to run over input files from the official Belle II data and MC.
The files on the grid are distributed on the available storage sites around the world. Fortunately, as a user you do not have to worry about their physical location. A file catalog keeps a record of where the files are located and you just need to provide a logical identifier for the samples of interest for your analysis.
Datasets and Datablocks
Each file on the grid is located using a Logical File Name (LFN), which always starts with /belle:
/belle/data_type/some_more_directories/dataset/datablock/file.root
When the LFN is provided to any of the gbasf2 tools, a replica is retrieved from catalog in the backend. You only need to provide the LFN(s) relevant for your analysis, without dealing with the physical location of the samples.
Files are collected within datasets, which can be located using a Logical Path Name (LPN):
/belle/data_type/some_more_directories/dataset
A dataset may correspond to a run for an specific experiment number in data, or a MC type in a MC campaign.
By design, a directory on the grid can contain 1000 files at most. For this reason,
the concept of a datablock was introduced. Each dataset is subdivided into directories with names subXX,
where the last two digits are sequentially iterated when the dataset is expanded to hold more files
(sub00, sub01, …).
In gbasf2, the data handling unit is the datablock.
The Dataset Searcher
The Dataset Searcher is an application on the DIRAC web portal (https://dirac.cc.kek.jp:8443/DIRAC/). You can find it from the Menu / BelleDIRAC Apps / Dataset Searcher.
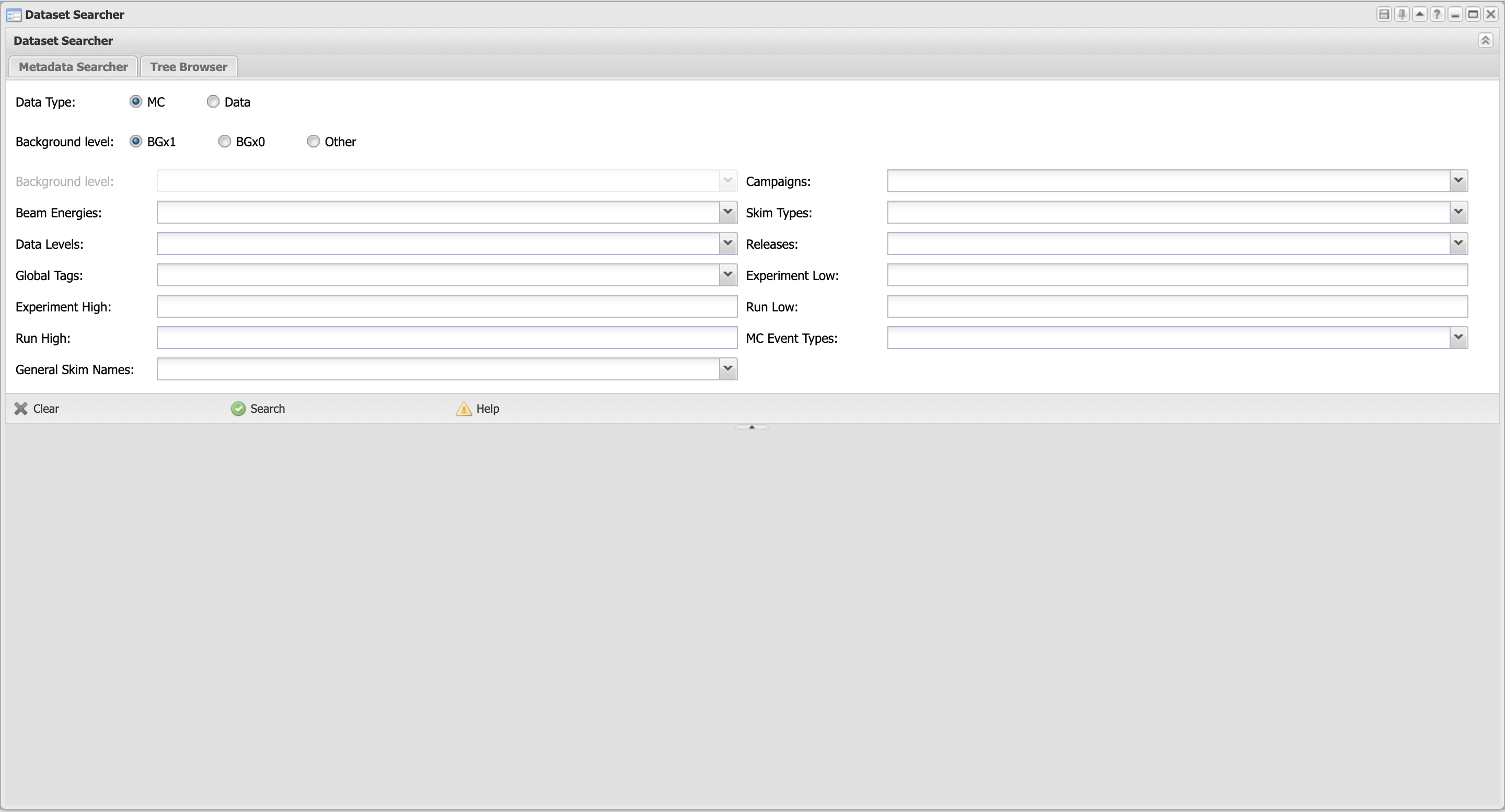
The categories available to search for datasets are:
- Data type
MC or Data.
- Background level
The beam background configuration used in simulation: BGx1, BGx0, etc (only for MC).
- Beam energy
Energy point in collisions: Y(4S), Y(5S), etc. Off-resonance collisions are specified by the energy in MeV.
- Data Levels
Indicator of the level of processing: mdst, udst.
- Campaigns
MC or data processing campaign name.
- Global Tags
Identifier of the database global tag.
- General Skim Names
First stage skim name (only defined for Data). ‘All’ means no HLT skim.
- Skim Types
Physics skim decay mode. See the software manual for details and the code of the available skims.
- Releases
Basf2 release version used to produce the dataset.
- MC Event Types
Physics EventType generated (only defined for MC). For generic samples use charged, mixed, uubar, ee, etc.
- Experiment High
Upper boundary of the experiment number in the datasets.
- Experiment Low
Lower boundary of the experiment number in the datasets.
- Run High
Upper boundary of the run number in the datasets.
- Run Low
Lower boundary of the run number in the datasets.
Search for the samples you want (e.g. Campaigns: proc11, Beam Energies: 4S, etc) and click on ‘Search’. A list of LFNs matching your selection will be provided.
At the bottom of the page, there is a button “Download.txt file” that can be used to get a list of LFNs in a local file.
The list of LFNs can be used to submit your jobs with gbasf2 (see Submitting jobs to the grid).
Note
The Data Production WebHome in XWiki is the entry point to find additional information about the samples that are available.
Searching for datasets via the command-line
Another way to interact with the Dataset Searcher is using the command line tool gb2_ds_search. It provides
options to search available metadata and datasets matching the query.
Searching available metadata
gb2_ds_search metadata will return available values for the metadata specified:
$ gb2_ds_search metadata --table <metadata>
For example:
$ gb2_ds_search metadata --table MCEventTypes
"charged"
"uubar"
"ee"
"3960640000"
"4190020000"
...
The list of available options are
- --help
Show the help message and exit
- --table
Table to search values from: Releases, GlobalTags, MCEventTypes, GeneralSkimNames, SkimDecayModes, Campaigns, DataTypes, DataLevels, BeamEnergies, BkgLevels.
Searching datasets
In a similar way as the Dataset Searcher on web, gb2_ds_search dataset will return the list of datasets
that matches the query. The usage is:
$ gb2_ds_search dataset [-h] [-o OUTPUT_FILE] [--campaign CAMPAIGN]
[--data_type DATA_TYPE] [--data_level DATA_LEVEL]
[--run_high RUN_HIGH] [--exp_high EXP_HIGH]
[--run_low RUN_LOW] [--exp_low EXP_LOW]
[--mc_event MC_EVENT] [--skim_decay SKIM_DECAY]
[--general_skim GENERAL_SKIM]
[--beam_energy BEAM_ENERGY]
[--global_tag GLOBAL_TAG] [--release RELEASE]
[--bkg_level BKG_LEVEL]
A full description of the options is available at Dataset Searcher tools .
Datasets and files metadata
Additional information related to the datasets and files located on the grid is stored in the metadata catalog. Metadata is the information about the data in concern. It is essential to correctly identify the input data for any kind of processing, like mdst production, skimming, or physics analysis.
Files, datablocks and datasets use a different metadata schema and therefore, information obtained from each one is different. See Computing Metadata in XWiki for details.
To retrieve metadata of datasets, use the command gb2_ds_query_dataset.
For example:
$ gb2_ds_query_dataset -l /belle/Data/release-05-01-03/DB00001363/SkimP11x1/prod00016031/e0010/4S/r04275/18530200/udst
udst
dataset: /belle/Data/release-05-01-03/DB00001363/SkimP11x1/prod00016031/e0010/4S/r04275/18530200/udst
creationDate: 2020-11-25 14:53:17
lastUpdate: 2020-11-27 02:11:42
nFiles: 1
size: 105046
status: good
productionId: 16031
transformationId: 348793
owner: g:belle_skim
mc: SkimP11x1
stream:
dataType: data
dataLevel: udst
beamEnergy: 4S
mcEventType:
generalSkimName:
skimDecayMode: 18530200
release: release-05-01-03
dbGlobalTag: DB00001363
sourceCode:
sourceCodeRevision:
steeringFile: skim/SkimP11x1/release-05-01-03/SkimScripts/singleTagPseudoScalar_Skim_Standalone.py
steeringFileRevision:
experimentLow: 10
experimentHigh: 10
runLow: 4275
runHigh: 4275
logLfn:
parentDatasets: /belle/Data/proc/release-04-02-02/DB00000938/proc11/prod00013369/e0010/4S/r04275/mdst
description: SkimP11x1 singleTagPseudoScalar skim on proc11_exp10r2_b1.
where the -l option displays the metadata to be easily readable. Notice that the metadata contains useful information
such as the parent datasets, a description, the steering file, etc.
Analogously, metadata of datablocks and files is obtained with gb2_ds_query_datablock and gb2_ds_query_file.
Using the same LPN as the previous example:
$ gb2_ds_query_datablock -l /belle/Data/release-05-01-03/DB00001363/SkimP11x1/prod00016031/e0010/4S/r04275/18530200/udst
/belle/Data/release-05-01-03/DB00001363/SkimP11x1/prod00016031/e0010/4S/r04275/18530200/udst/sub00
lastUpdate: 2020-11-26 04:03:35
nFiles: 1
status: good
creationDate: 2020-11-26 03:45:54
size: 105046
You can easily see that the dataset contains an unique datablock, and the datablock contains only one file. Retrieving the metadata of the file can be done providing the LPN of the parent datablock:
$ gb2_ds_query_file -l /belle/Data/release-05-01-03/DB00001363/SkimP11x1/prod00016031/e0010/4S/r04275/18530200/udst/sub00
/belle/Data/release-05-01-03/DB00001363/SkimP11x1/prod00016031/e0010/4S/r04275/18530200/udst/sub00/udst_000001_prod00016031_task94274000001.root
jobId: 174693183
checksumType: Adler32
runHigh: 4275
experimentHigh: 10
eventLow: 325
guid: B6D9ED03-EEA5-42B5-5DDF-550F9716E91C
status: good
site: LCG.Napoli.it
eventHigh: 1508
checksum: d9fd3a15
parentGuids: 4A487D03-0B18-2DB0-96F4-D9E2CB78EE21
nEvents: 11
runLow: 4275
experimentLow: 10
date: 2020-11-26 03:50:35
size: 105046
A full description of the usage and options for the command line tools is available at Dataset management tools.